The data engineering team at cabify
We use heavily Google’s infrastructure to delegate the administration of many of our data needs. We like to focus on features and Product instead of operations, we like to focus on our Riders and our Drivers.
This is a small article about our first thoughts by using Google’s Dataproc and BigQuery
A bit of background
Data Engineering team in Cabify is rather new and small. We have experience working with data in big teams of mixed profiles joining SysAdmins, DevOps and Developers.
For us it was important to do data analysis over big amounts of data as soon as possible and do not spend months in building the infrastructure. We are growing very quickly in many countries around the world and everybody need insights. We didn’t have very special needs for our data platform and we could adapt to existing solutions that could help us to develop ASAP.
We had many options, being the most common AWS and Google Cloud. We did extensive research about which will give us the best trade off between managed services and flexibility and we finally chose Google Cloud.
BigQuery
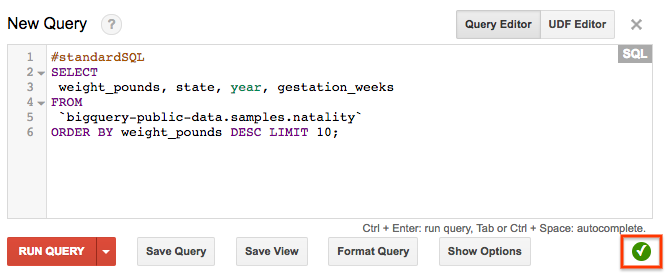
Our first approach on Google Cloud Platform was with Google’s BigQuery. We had a single PostgreSQL instance that was growing too much in a huge machine. The machine was really expensive and our BI team couldn’t do lot of analysis with it anyways because of endless JOIN operations and complex queries.
A distributed SQL-like solution like BigQuery with a connector with Tableau (our analytics platform) seemed like a good idea for BI while the Data Engineering team could focus on map reduce like jobs over plain text.
The first test
To try BigQuery, we created a very simple dataset and table to store our logs from server. Papertrail leave our logs in S3 (please, people from Papertrail, if you are reading this, we will happy with a GCS alternative too ;) ) so we just had to read them and upload them to BigQuery.
The first test was to try to find some insights about some unexpected tradeoffperformance behaviour we were having intermittently so we stored in BigQuery like 5 Tb of logs to check.
We did the query in BigQuery and… bam! 10 seconds later we had the results. 10 seconds for 5 TB? really?? If you have worked with Apache Spark or Apache Hadoop you know how “slow” is to do a simple filter on a cluster. Just the overhead of creating the job in the cluster would eat those 10 seconds. I’m still trying to make the maths of the cluster size and price to get this answer in only 10 seconds. In fact, I think it’s quite difficult to have an answer so quickly in any of the current OSS solutions without having a huge cluster underutilized.
Google’s Dataproc is also impressive
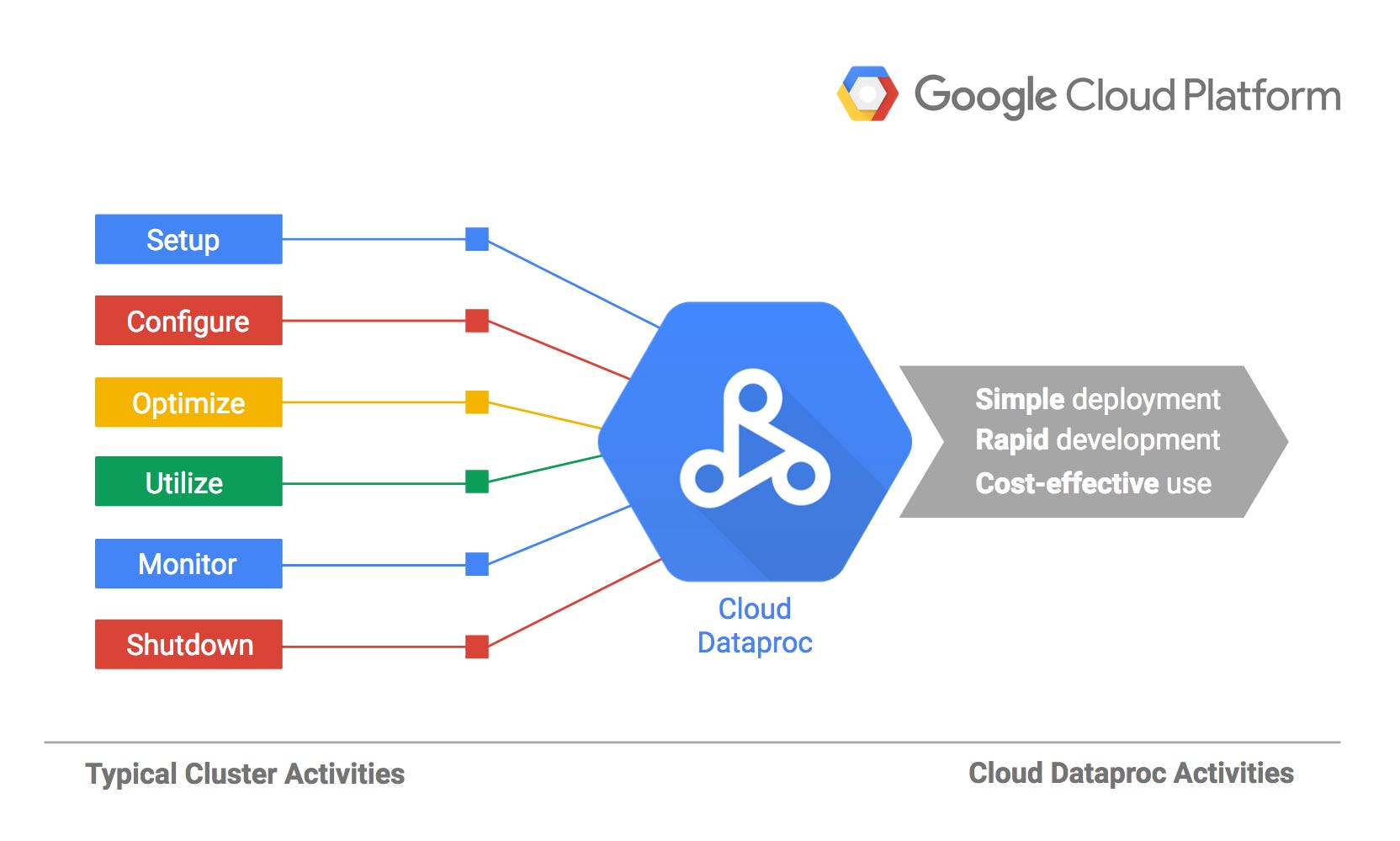
The idea of a managed Hadoop/Spark cluster is also very nice. To deploy a Spark cluster is really quite consuming if you aren’t doing it every day. Also the “problems” you could have with Scala / Java versions between Spark, the scheduler and your job can also be frustrating.
We are also using Dataproc mostly for ETL jobs, to load data on BigQuery and to clean and prepare outputs for the Data Science team so that they can load them easily in Jupyter and do machine learning with them. They used high memory machines where they can store hundreds of gigabytes of data in memory but sometimes it’s just easier to pre-filter the data before doing research.
Preemtible machines are also a really nice feature. One of the main problems in big data clusters is resource allocation and optimization and to have 100 machines adding 800 CPUs and 2.4TB of RAM to your current cluster for 8 dollars is simply obscenely cheap.
Google’s Dataflow
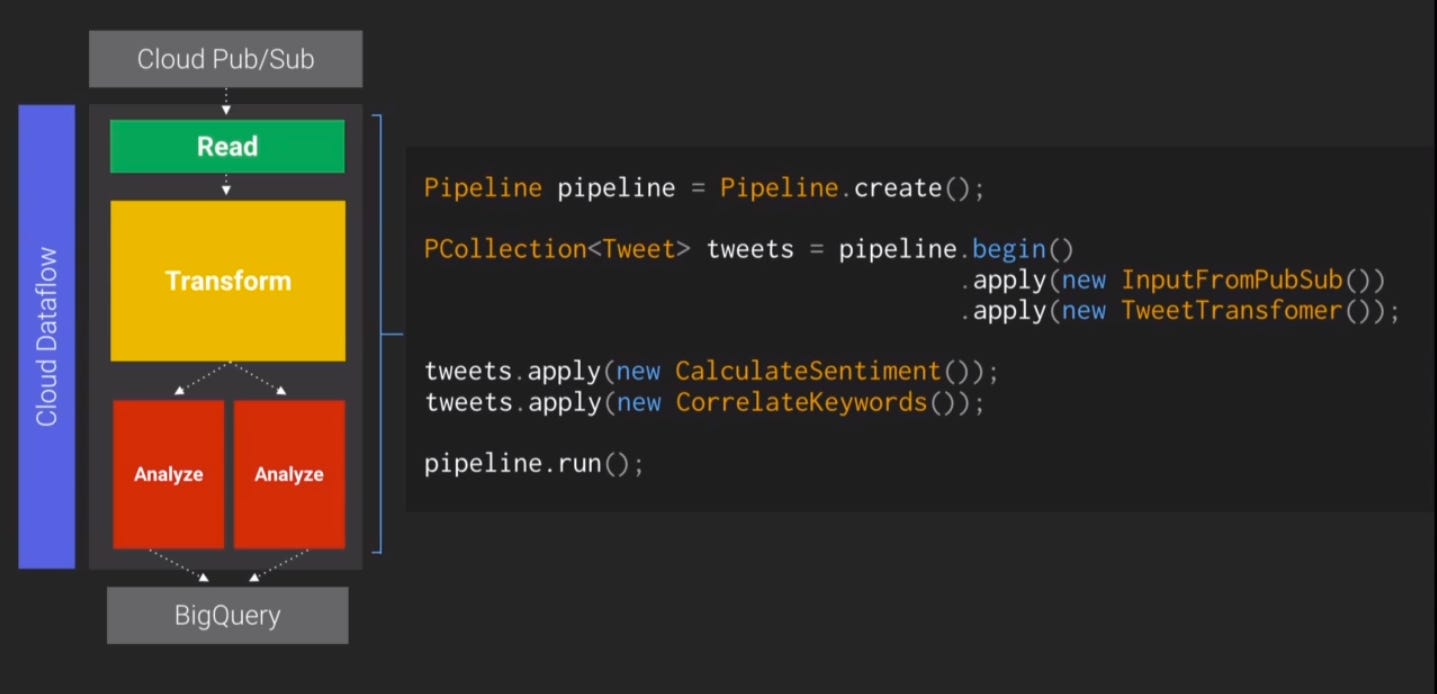
The last tool we’re starting to use since its 2.0 release on top of Apache Beam is Dataflow.
The new programming model of Dataflow is nice but quite confusing at the beginning. We want to develop our jobs in Python if possible as we are not a JVM company and just few of us have experience to code in Java or Scala. Unfortunately, Python support is incomplete yet and we can only do “simple” things with Python’s Beam implementation at the moment. We are developing some Java jobs without problems.
Something that we really like about both Dataproc and Dataflow is that you don’t have a vendor coupling feeling when you work with them. Looking at the code of our jobs you don’t see traces of any of the providers. So even when you code this solutions to deploy them in Google Cloud, you can pretty much take them to run on any other provider without too much hassle.
Conclusions
-
If you have experience with SQL OLAP solutions we really recommend to try Google’s BigQuery.
-
Dataproc looks a lot like a cluster where you can manually manage many features but it’s still quite managed (I would say that it’s similar to AWS EMR in some aspects)
-
Dataflow could be the next “big thing” for distributed computing, give it a chance if you can, it’s really worth it.

We are hiring!
Join our team and help us transform our cities with sustainable mobility.
Check out the open positions we have in .