Our frontend stack

The journey we started in 2011 when the first rider used our app has led Cabify to create tools to support riders along with the countries we operate. First, we created an Admin based on Rails to allow our operation team to do basic CRUD operations. Then the first big tool appeared to encourage Business users to use Cabify. This was back in 2016 when our team chose a Single Page Application based on React and Redux (it was super trendy at that moment if you remember).
Basics
React
We embraced React at that moment and we’ve never betrayed it since then. This is because React has an incredible adaptability and a huge community but also because React is a straightforward API to HTML (and other UI technologies). Since more than 20 engineers are working on Frontend applications, we need something closer to what we understand as a standard. There are, of course, more adopted technologies (such as Angular), but as I said before, this straightforward implementation of HTML allowed us to avoid increasing the complexity of the projects. This is something we at Cabify have in our DNA: avoiding opinionated abstractions as much as possible.
Typescript
We use Typescript as the main Javascript superset. Typescript has been an incredible tool to gain confidence in our code when dealing with big applications. It also has helped us to define better libraries and components. We achieve an application with 0 runtime error reports just using Typescript in every file. On older applications we still have Javascript code, at this moment, we’ve already migrated half of the code to Typescript in less than 2 years.
Redux
It always came to Redux as a de facto library when dealing with the state. This may be the first reason we embrace this tool in the first moment. Over time our applications were getting bigger and bigger, we soon realized that the traditional approach of Redux was messy and hard to maintain. Our biggest project has more than 620 action creators (some of them with async actions), more than 400 selectors and more than 250 reducers, and approximately 10 cross slice reducers, this results in creating a simple feature to add ~10 files for a simple fetch.
We’ve made some explorations on using the new Redux Tool Kit and it seems to reduce the number of files to be created to do the same thing, which is great. We’ve improved the maintainability of redux elements when embracing typesafe-actions to create strong typed actions and reducers, but didn’t reduce the number of files to be created. To handle Redux side effects (called epics), we adopted redux-observable because it uses RxJS which is widely adopted for reactive programming.
In the end, we are using Redux less and less because it increases complexity over new applications, most of the newer front ends rely on Context API more or aren’t SPA anymore.
UI
Design system
I won’t talk about how a Design System came to our Product organization, but after 3 years, I’m proud to announce that we have a basic UI kit to create our interfaces. This kit consists of a library that exports React components and basic stylesheets. This library consumes another library which is periodically updated with tokens handled by our design team directly. This means that engineers don’t have to be aware of color adjustments from designers who maintain the Design System.
SASS and PostCSS
I’ve talked about having shared components crafted closely with the design teams, this allows us to not rely too much on custom CSS. But sometimes, we still need to define custom styles in our projects. Since the beginning of Cabify’s frontend applications, we have been writing stylesheets with SASS because we can easily define different files for each component and define and share values between projects and stylesheets.
We also rely on PostCSS to delegate custom rules for different browsers and also we do a few conversions here: we use postcss-plugin-px2rem currently, and we’re deprecating a custom PostCSS plugin to create a custom syntax to define border without thickness (based on border-shadow CSS property). We highly discourage creating custom syntax, this is non-standard and could cause a collision with incoming CSS syntax.
Finally, we have included SASS unit test suite sass-true for our Design System library components.
Storybook
Having a testing bed for components is super handy for several reasons: to document components, to actively develop them, and to test them. This is why we find Storybook a super useful tool because it seems to be focused on everything we need as maintainers.
It has a great API to create a component playground, it can read Typescript Props interfaces and show them as documentation and also allow us to use MDX templates to go further on this purpose. It also allows us to define different variants of each component, so it allows us to build our component in real-time without having our whole development suite up. And finally, we rely on a great plugin called loki, to perform visual regressions on our components. This is great to increase trust on every deployment. The only downside of this tool is to run it on CI. With limited resources machines, a Docker image running a headless Chromium could be difficult to run in good time or without having timeouts.
Internationalization
As a company (de Madrid) that targets people from every place, we need to make it easier for them to reach our product. This is why it is a 1-day requirement to have our platform in different languages. We decided to rely on a library called polyglot, maintained by Airbnb for key translation, pluralization, and interpolation. We’re not exactly relying on polyglot directly, but in our own public library called @cabify/redux-polyglot (which is in fact a fork of redux-polyglot).
Dealing with key-translate files is a PITA because if you are not careful enough it can result in phantom keys, this is why we decided to explore new solutions, such as tools to extract keys from the code and recreate the file every time there is a new key defined in our view layer.
This is why we decided to use i18next, which encourages you to extract the keys from the codebase and also provides a nicer React API.
Testing
Jest and testing
Since the beginning of the Cabify frontend application testing has become an essential part of our workflow, this is why it was key to test implementation success to have a tool to convert a tedious task into an easy one. Jest has all the things we need to run tests effortlessly. Recently we have set up our continuous integration to display test reports with jest-junit, this allows us to have all the error reports at a glance, without browsing any pipeline verbose step.
Jest also has great performance, we deal with more than 1500 suites on our biggest project, running on one of the latest Macbook Pro i7 in approximately ~100 seconds, around 30 seconds on a regular Macbook Pro M1.
What are the key things to test in Cabify? Well, first we do unit testing on everything (even React components, see below). Second, we found it useful to do functional tests on certain user interactions, such as our Journey builder (the form you use to ask for a journey in Cabify). We found this functional not so useful because we render the whole application within the React test environment mocking everything from the frontend. This test can be unreliable since it requires a lot of resources and a fine adjustment for the environment.
Third, we found it useful to perform Redux store tests as we had a huge amount of reducers and epics (Redux side effects). After a few years of dealing with this test, we haven’t found them any useful at all because with every Redux state change we needed to perform changes on them, finally, we decided to not create any store test anymore.
Last but not least, we relied on Cypress (which is also running with Jest) for end-to-end tests along with the Cucumber framework.
React Testing Library and Enzyme
As I mentioned before, we consider unit testing a key part of our workflow, so it is to test our UI components. First, we started using Enzyme, mostly testing on nodes directly by querying them with a className, also updating the component with new props to test different situations.
But two years ago* React Testing Library* gained popularity and somebody encouraged all of us to take a look. The main reasons why we decided to adopt RTL are:
-
Tests now are focused on accessibility, this forced us to pay attention to accessible properties and semantic components, this is where tools like _react-polymorphic-types _and Chrome dev tools accessibility inspector came along.
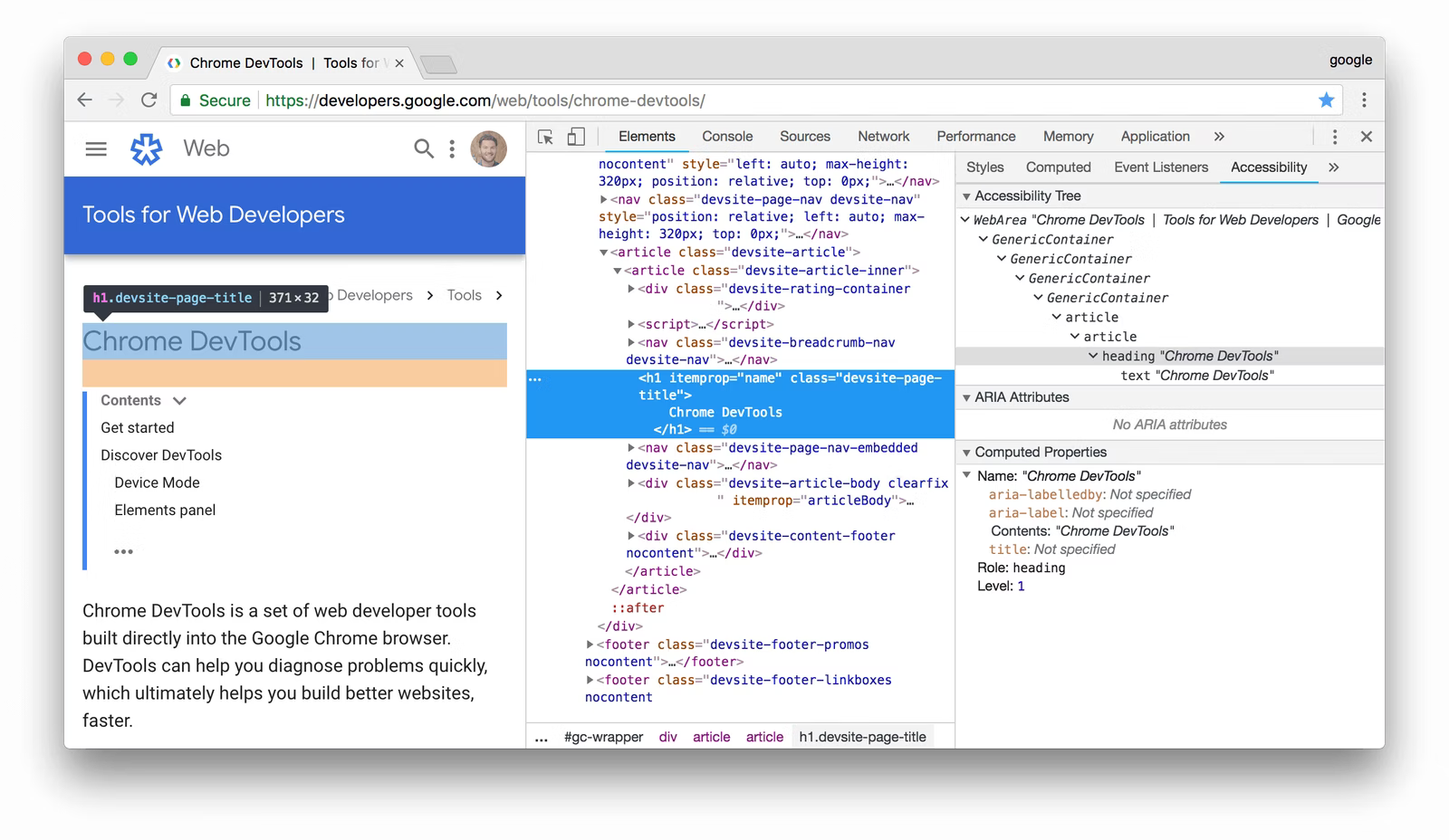
-
Basically, Enzyme is dying. The latest versions of React are not supported officially and also have a lot of issues dealing with hooks.
Loki
If you are not familiar with Visual regression testing, imagine testing the impact of a stylesheet change with a change of layout. You can visually test if something has changed using a diffing tool to detect pixel-level changes.
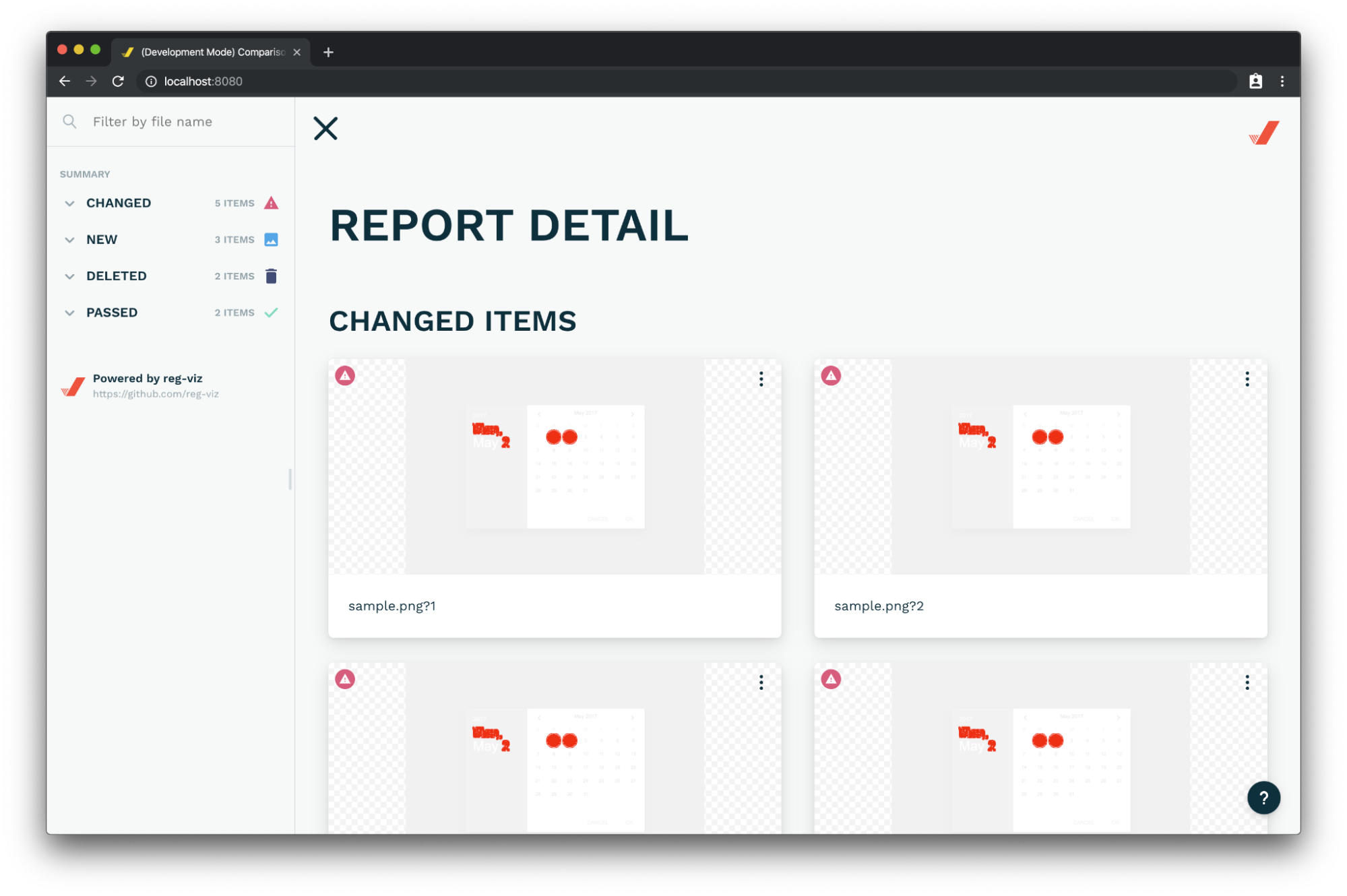
To do independent tests we rely on Storybook to compose test variants and different cases, and we take snapshots of those compositions and we save them in a compressed image file, we put those files into our git repository as our test source of truth. Then when running these tests, we generate these image files again and they should match with our previously generated files. We define a 1% difference threshold to avoid test flaws and negligible changes.
To perform these tests we relied in the past on BackstopJS, but this became hard and hard to implement over time, and also had a really bad performance (more than 10 minutes to test the whole suite). This is why we decided to find an alternative and we found Loki, which is easier to implement with Storybook and also faster than BackstopJS. We encourage you to take a look at this project since it is actively maintained and has barely 0 configurations. The only downside is this relies on a headless Chrome to perform tests in the CI, which requires more resources than expected.
The image above shows a reg-cli web output, which uses loki diff on references to show what has been changed with a pretty UI.
ESLint, Stylelint and Prettier
You all know about linting, there is nothing much to say about its usefulness. We started using the Airbnb ESLint preset but we got tired of having rules changes on every library update. This is why we decided to fork this configuration and recently we published this configuration as an Open source project on Github (you can take a look right now!). It is great to have a lot of autofixable rules, so we don’t waste time accomplishing tedious modifications on code to fulfill ESLint requirements. We also use Stylelint to do the same things with CSS files, nothing much to add here. I consider a great feature its ability to automatically sort all the CSS properties.
The main purpose of this tool is to guarantee a homogeneous code style among all of our codebases. It also prevents us from introducing bugs to our code (take a look at React Hooks ESLint recommendation).
We also use Prettier to maintain format basics like Quotes or indentation.
Recently we discovered a tool to detect what files remain unimported, and include it as a CI job to avoid pushing code to main which is not used anymore. We discovered about 70 files not used and ready to be removed, reducing the cost of maintenance.
Tooling
Webpack and Rollup
There is no discussion about what to do to create bundles on SPA. Basically, Webpack provides us all the flexibility when dealing with imports, lazy loading, and code transformation. It is true that sometimes the configuration gets hard, this is why we share our Webpack config as an NPM private package. This configuration supports Typescript transformation via Babel (we have our Babel configuration as Open source, check it out!), to import SASS stylesheets and transform them with PostCSS, creates an HTML file with all the imports, and also exports a JSON file which contains the files that Webpack has created to be consumed by a template engine in the backend, serving the HTML with Javascript and CSS file paths appended.
We also use Webpack Dev Server to run the project in development mode.
To create library bundles we use Rollup, which basically transforms Typescript with Babel and copies SASS files into the bundle. Using Rollup we don’t require too much time and resources to create bundles. You can check the Rollup configuration here!
Gitlab
We run our own Gitlab instance not only to host the codebase but to do Continuous integration for our services and run configuration. But the most important thing for Frontend development is the private Package registry, we first decided to run a Verdaccio registry but we decided to go with Gitlab because it was already maintained by our infra team so that we would not take care of another service.
We feel super comfortable with the pipeline system and job definition. We use our self-built and hosted Docker image to run the jobs but to avoid creating a new job on every repo, this configuration is shared between our projects, which is great. We’ve dealt with Github Actions recently but we still need more experience with them.
Lerna
When dealing with libraries it is reasonable to create different libraries for every little thing, but suddenly you will find out that you have dozens of them. We came up with Lerna which allowed us to share configuration and repo between similar libraries. This means that all the libraries in a single “monorepo” will be pushed at once (when a library does not contain any change, Lerna skip that library publication).
Renovatebot and Dependabot
We found a great ally when dealing with outdated libraries. In our own Gitlab library we use Renovatebot, this bot will check for library updates and create a merge request once a week for external libraries, and once a day for our internal libraries. It is so important to have unit tests and type checks on basically everything because it is easy to introduce bugs and errors in your libraries. We trust our code when a pipeline is Ok, this is why we automatically merge updates with all of our tests suite working.
We have the same thing for Github with Dependabot, but Renovatebot is super configurable. I’m sure Dependabot will be in the future as well.
But sometimes this library’s updates do not work well and require changes in the code. Who does the job? Well, we share this duty among all of the Frontend Engineers, dedicating an hour a week, one person per week. I’m proud to admit that we keep all our codebase up to date every week. A great thing about Renovatebot is that allows you to define how often do you want the bot to create a Merge Request, also allows you to group them depending on its name. For example, we receive once per week updates grouped by ESLint packages together, this is useful to avoid completely different package updates to make a pipeline fail, making the job of looking for what’s going on harder than usual.
Prometheus
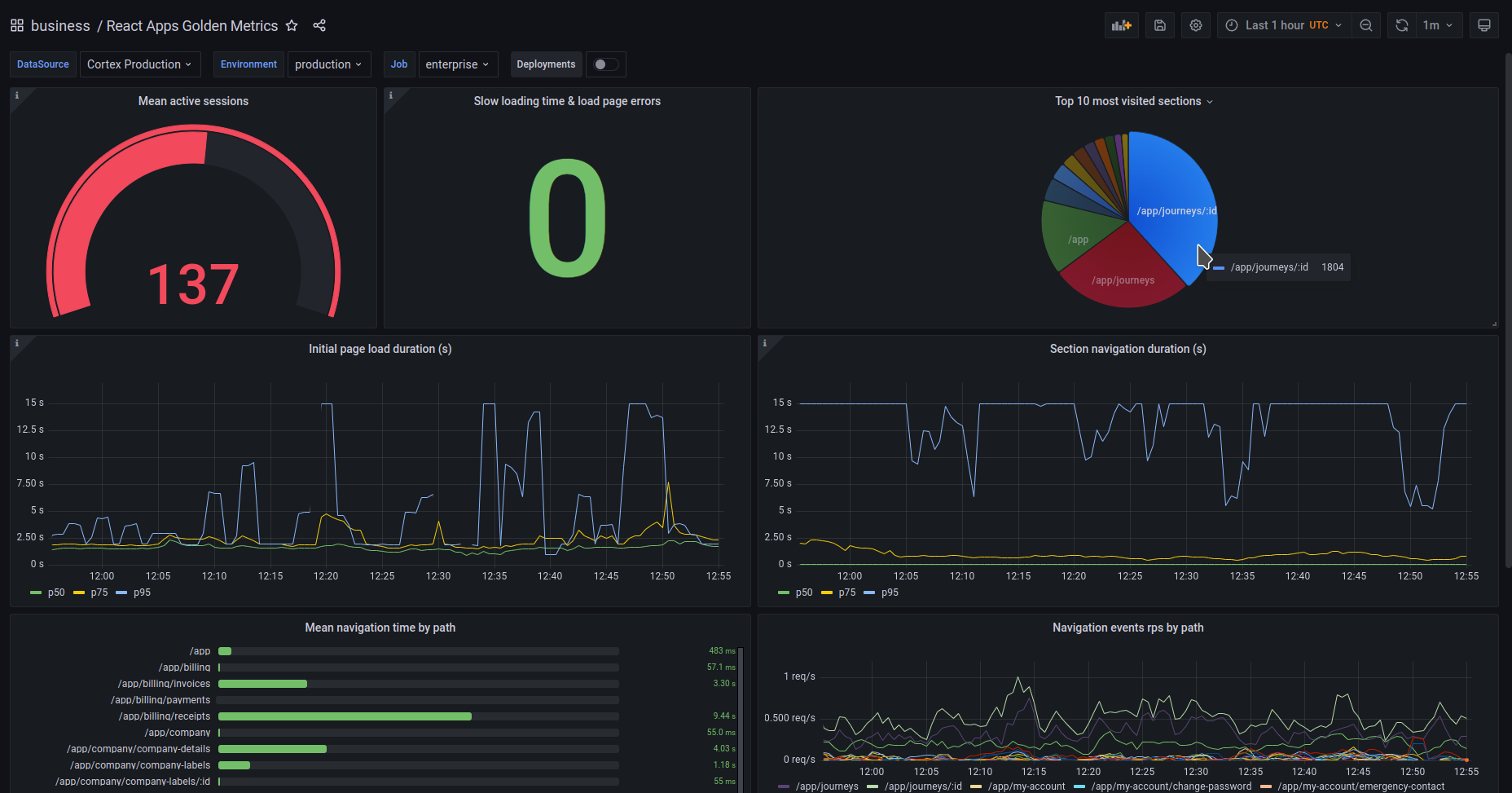
At Cabify we use Prometheus to obtain metrics from our services. The information we are interested in obtaining from our Web applications is how much time does the application takes to have a meaningful render and how long it takes to route to another page. This implementation relies on an Open source library developed mostly by Javier López Pardo called @cabify/prom-react.
Amplitude and Rollbar
To report errors at runtime we use Rollbar combined with a Redux Middleware. This is great because it allows us to have visibility on common errors. We also found super useful the Slack integration with Rollbar so we can be aware of what’s going on, or if a deployment went bad.
On the other hand, Amplitude allows us to analyze user interaction with the platform, decide on goals and make decisions about the product. Amplitude is super easy to use, creating a new dashboard and charts is effortless. We also have a middleware to report events to Amplitude. In case you don’t know what Amplitude is, I encourage you to see their product on the web, but for short, allows you to define custom events to track user behavior on the web.
Conclusion
I’ve covered almost all of our Frontend Technologies here. Most of them are de facto standards in the industry and none of them have an unjustified reason to use them. This is because most of them have been developed for years and have been widely tested. I’m confident to say this because our frenzy library update policy has been super easy to maintain over the last 2 years.
If you find any of this interesting you can always take a look at our Technology blog (cabify.tech) where you can find more content about how we work at Cabify, also if you are interested in joining the Product team you can always take a look at our Cabify careers homepage, we have plenty of Remote and Onsite opportunities.
People who collaborated in creating this article
- Abel Muiño
- Alejandro Frías
- Ignacio González
- Jesus Merino
- Ricardo Boluda Hernández
- Rodrigo Erades Alonso
- Yago Quiñoy Lobariñas

We are hiring!
Join our team and help us transform our cities with sustainable mobility.
Check out the open positions we have in .