A tale of a search of a cep engine and real time processing framework
We have been looking for a CEP for some time now. If you don’t know what a CEP is, the Wikipedia article explains it pretty well: https://en.wikipedia.org/wiki/Complex_event_processing.
There are many CEP engines in the market with a wide spectrum of possibilities. They are commonly used in fraud detection systems and in IoT pipelines. They are similar to https://en.wikipedia.org/wiki/Business_rules_engine and many people confuse them but they aren’t exactly the same. While the differences are subtle, today’s we’re seeing a new rise in CEP engines thanks to Event Driven Architectures.
Our needs, expressed as MoSCoW priorities are simple:
-
It must be updated without downtime.
-
It must provide scalability, workload distribution and high availability.
-
It must be easy to reason about
-
It should support some kind of DSL for business guys.
-
It should be mostly stateless (see below).
-
It would ideally be a managed service but not a full platform (see below).
-
It should work within a container.
-
It should be easy to use and easy to maintain, even for post-graduates.
-
It could support some kind of stateful actions for windowing operations.
-
It won’t be a dedicated platform/product with a ton of front-end features that could potentially limit us in the future or force us to develop new features around it in less than ideal ways.
We have considered a few options for our needs:
-
Apache Flink (JVM) which has a built-in CEP engine.
-
WSO2 WSO2 Siddhi (JVM) can be used as a library and also has its own platform. It has a DSL
-
Google’s Dataflow (JVM, Python, Scala with Spotify’s Scio) Not exactly a CEP engine but can be used in a similar fashion. Interestingly it can use Flink under the hood.
-
**Apache Heron: **Developed at Twitter to replace Storm. It works on Apache Mesos
-
**Apache Storm **Originally developed at Twitter, it’s being replaced with Heron.
WSO2 Siddhi
We started with WSO2 Siddhi because one of us had some experience with it and we already have some jobs using Google’s Dataflow.
We downloaded WSO2 Stream Processor which comes with an online editor for their DSL, which is SQL based. After launching it and pointing the browser to http://localhost:9090/editor you can see the following editor:
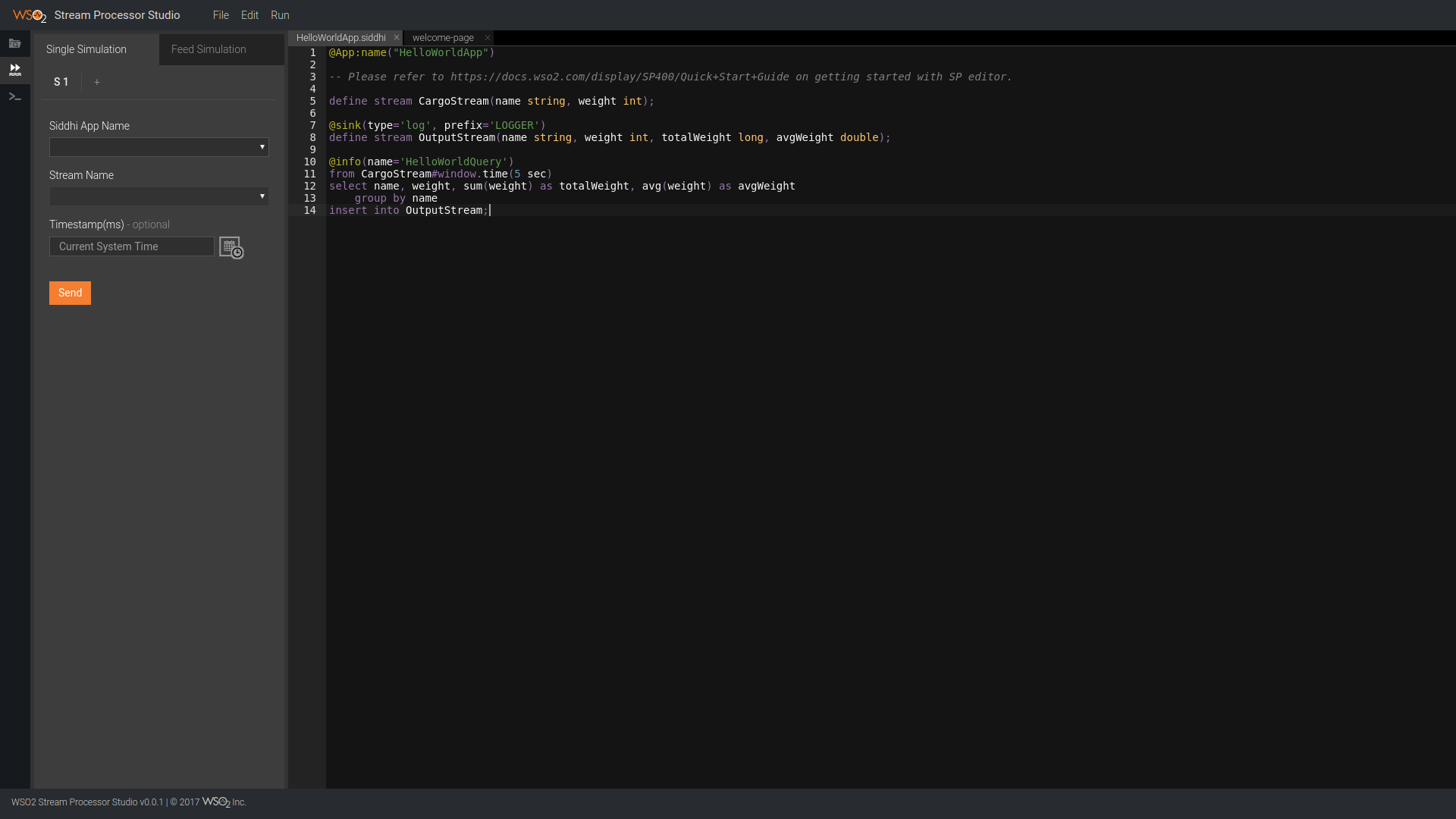
The code that can be seen is the SQL based DSL which is quite simple to grasp and play with. This particular piece of code makes a windowing aggregation of cargo weights by outputting the weight, average weight and total weight grouped by name on the last 5 seconds. This is achieved with this pieces of code:
1
2
3
from CargoStream*#window.time(5 sec)
*select name, weight, sum(weight) as totalWeight, avg(weight) as avgWeight
group by name
Not bad, considering that a DIY solution of this simple problem would take many more lines of code. Ease-of-use is a 5/5!
It can also be used as a library, delegating execution and life cycle to the main program that can be deployed in a container transparently.
Unfortunately, it seems that the High Availability is kind of complex and not very trustful. It’s really noticeable that in its core it wasn’t developed to be a distributed solution and it’s visible in how the HA is achieved. This gives it a score in Reliability of 1/5
Also, it seems like a bit difficult to operate in terms of Systems. This is an Ops 2/5
It’s a bittersweet feeling because the DSL seems like the perfect solution for business.
-
Ease of use: 5/5
-
Flexibility: 2/5
-
Reliability: 1/5
-
Ops: 2/5
Spotify’s Scio on Google’s Dataflow
The guys from Spotify have a lot of work done over Google Cloud Platform and we usually keep an eye on their OSS work because they are facing similar problems to the ones we have.
Spotify Scio is a Scala implementation with steroids of Apache Beam model to run on Google Dataflow. It will solve all our scalability and high availability problems. It really looks a lot like Apache Spark which is a nice feature because it lowers the entry barrier.
A simple wordcount in Scio looks like this:
1
2
3
4
5
6
sc.textFile(input)
.map(_.trim)
.flatMap(_.split("[^a-zA-Z']+").filter(_.nonEmpty))
.countByValue
.map(t => t._1 + ": " + t._2)
.saveAsTextFile(output)
You wouldn’t say that this is Apache Beam code which make me think that we’ll have to deal with two different syntaxes (Java/Python and Scio) of the same programming model that does the same thing under the hood but with differences in how they look. However it’s a small drawback that will probably only annoy the less experienced engineers.
Everything else works mostly like Google Dataflow, being able to test a pipeline locally, run a DirectRunner and deploy from your laptop by using the DataflowRunner. So Ops is a 5/5 and Reliability score is a 5/5.
The drawback is that Dataflow doesn’t have a CEP engine as we know it and we will have to develop a business DSL as well as most of our operations. Also, Apache is developing SQL on the Beam model and it will take time until it’s implemented in Scio. So Ease of use of 2/5 but Flexibility is a 5/5.
-
Ease of use: 2/5
-
Flexibility: 5/5
-
Reliability: 5/5
-
Ops: 5/5
Apache Flink
The last option we have considered is Apache Flink. It comes with a CEP engine and it seems like the balanced solution between Siddhi and Dataflow.
It can be deployed in Google’s Dataproc so we can consider it a managed solution. The first drawback we see is that we’ll under-use the cluster as we don’t have more Flink jobs (batch or streaming). So it gives a Ops score of 3/5 because we still have to control when to shut down the cluster and try to maximize its use.
Take from Flink docs, a simple execution flow looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
**val** input**:** **DataStream[Event]** **=** **...**
**val** pattern **=** **Pattern
.**begin**(**"start"**)
.**where**(_.**getId **==** 42**)**
**.**next**(**"middle"**)
.**subtype**(**classOf**[SubEvent])
.**where**(_.**getVolume **>=** 10.0**)**
**.**followedBy**(**"end"**)
.**where**(_.**getName **==** "end"**)**
**val** patternStream **=** **CEP.**pattern**(**input**,** pattern**)**
**val** result**:** **DataStream[Alert]** **=** patternStream**.**select**(**createAlert**(_))**
The code is very simple to understand. 3 events that must arrive in the order of ID 42, volume equal or higher than 10 and finished with the name “end” will trigger an Alert. Unfortunately, the documentation is good but you can’t find much material to learn about it so its Ease of use is a mere 3/5. Like Scio, you can implement almost everything so it’s a 5/5 on Flexibility.
While Flink CEP looks fine it doesn’t really solve our current problem when you consider the drawbacks it gives.
-
Ease of use: 3/5
-
Flexibility: 5/5
-
Reliability: 4/5
-
Ops: 3/5
Conclusions
We have made a small score table to compare our view of a few products we could use as CEP engines.
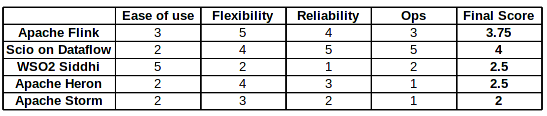
We haven’t written our conclusions about Apache Heron and Apache Storm, products developed by the terrific people at Twitter because since the beginning, it looked like they were far from covering our needs.
Apache Heron and Apache Storm could potentially cover our needs but they seem really big products to build simple CEP like dataflows and ETL’s. Apache Heron also comes with the need of deploying a YARN or Mesos cluster which crashes directly with our need to be a fully-managed service with little or no overheads for the Systems team.
Of course, to compare Siddhi and Heron is like to comparing apples with oranges, but limiting both to our needs they have a similar score. The same goes with the rest of the products.
Scio on Dataflow seems like the best candidate but we really don’t see so much advantage in using a Scala version of Dataflow over the Java 8 based implementation of Apache Beam. It will give us expressiveness and reduce verbosity but it will be difficult for newcomers and post-graduates to write and maintain their own code.
Unfortunately, none of them comes with a DSL for our business people and we’ll probably need to implement our own one. This requires time and it won’t be so easy for newcomers to understand, so we’ll have to think hard about how to do it.
What do you think? Maybe it’s better to use Flink so we avoid vendor locking? Maybe vendor locking isn’t so important but we should stay with Apache Beam in plain Java?
A note about Kafka Streams
Yes, we also briefly considered Kafka Streams for this use case but as our broker is already Google Pubsub and Kafka is a pain to operate, it was simply out of any discussion.

We are hiring!
Join our team and help us transform our cities with sustainable mobility.
Check out the open positions we have in .