The cabify engineering stack 2020 edition
Since Cabify became the first European app for VTC vehicles in 2011, things have changed a lot. Millions of journeys, riders and drivers use our platform. On this journey, it has led to a product team of over 270 members all working together to archive our mission.
Cabify has more than 280 services, with an average of more than 270 weekly deployments to production and 11,000 to testing environments. All this growth has required that our stack and infrastructure have evolved and changed in all these years.
This is a high level/introductory post about the inner workings of Cabify. We will start by looking at the infrastructure where Cabify runs, how we use it and monitor it at runtime, how we approach backend, frontend, mobile and our big data infrastructure. We will finish with the QA approach.
Platform and SRE: build in the clouds
At the beginning we ran our things, written mainly in Ruby which was later accompanied by Node, which was finally replaced by Go, in a mix of bare metal and VPSs in Softlayer (now IBM Cloud). We also used, and still do, CouchDB and Redis with some home-grown metrics & monitoring. In those early days our most critical Go services ran as a single instance. A simple binary on a machine and with releases that implied downtime.
With exponential load increases and great pain, we soon realized that we needed the scalability and flexibility of the Cloud, in addition to many other factors such as additional services: MySQL databases as a service, PubSub, Object Storage…And just like that, the decision was made and the migration to the cloud begun. Now, after an *interesting *journey, we run all of our workloads in Google Cloud and AWS, except CouchDB, and we are practically independent of the provider. We use Terraform and Ansible to describe our infrastructure and the IT automation.

Our business is not building datacenters, pull cables or manage machines, our focus is running things that support our product. We have a Infrastructure group that provide fundamental services like runtime, monitoring, networking, and others to the rest of the organization. They provide a cost-effective, self-service infrastructure for internal customers of the company. We also have a Builder tools team that aims to simplify complicated workflows within our Infrastructure. All of them enable the team to deliver value without having to worry about the details of the lower layers, while preventing SLA inversions and reducing waste…
The services run in our Nomad cluster but we are migrating to Kubernetes. The first achievement has been the release of our Kubernetes Testing Environments (KTEs). KTEs are able to run the whole Cabify product end-to-end on a cluster. And we have tens of them (as many as needed).
For the persistence layer we use mainly MySQL as database. We have a CouchDB under our Ruby on Rails monolith. We have some Postgresql, Redis, Elasticsearch and Memcached. We mainly select the motor engine based on the task. Immense work has been done to have the tools to manage self-serviced databases: backups, read-replicas, monitoring, schema migrations…
Traefik handles the service mesh layer, providing a transparent way for services to reach other services. We also have Nginx on the edges and where it is required.
We are moving towards a platform based on event collaboration, so the messaging infrastructure is very important to us. We use Google Pub/Sub and NATS for messaging. We created the Message Bus as a Service (MBaaS), it is an internal tool developed to abstract the complexities of messaging systems. MBaaS currently uses Google Pub/Sub for reliable delivery (at-least-once) and NATS for real-time with unreliable delivery (at-most-once).
NSQ is the message brokering solution that we use internally on the Realtime platform. It is the chosen one when we need latencies of less than a millisecond.
Deployments, monitoring and observability

Mainly we build Docker images that we push to Google Cloud Registry. Application configuration and deployments are powered by our in-house tool. Our code lives on GitLab and we use GitLab CI/CD to support our continuous methodologies. We also use Bitrise for the mobile apps.
The services log files are collected by Fluentd and shipped via Logstash to ElasticSearch. We use ElasticSearch as a backend, and have Kibana as the frontend. Kibana is supported to view and search stored logs.

All metrics are gathered with Prometheus, stored in Cortex and displayed in Grafana dashboards. We have a Grafana SSoT based on a code-based lifecycle, by using a GitLab repository. AlertManager is used for alerts, which trigger pages in VictorOps for relevant services.
We also use Rollbar to collect and report errors and Datadog to collect metrics related to our services and business. Datadog makes different trade-offs than Grafana and provides longer retention period, allowing us to see mostly or yearly trends. In addition, Datadog is the chosen solution as APM, we use it to monitor and manage the performance and availability of our software artifacts.
We need to know what happens at all times and with our stack we are able to have full observability of our services.
Backend: (micro)services galore
Cabify is moving away from monolithic solutions. We have 280 services deployed communicating in loosely coupled ways among them. Cabify was initially coded as a single Rails application, and it is still a central piece for running the business. Many of the new services depend on it and the project is very active with 101 contributors and an average of 8 daily commits in the last year. Leaving the monolith is the responsibility of each squad.
Outside of the monolith, most new services are written in Go or Elixir, but we keep using some Ruby when it is the right tool.
We have Servant, a library designed to facilitate the implementation of (micro)services written in Go programming language. It provides a lot of functionality with all the basics like: logging, monitoring, metrics, database connections, migrations, reporting, caching, task execution and integration with the MBaaS, HTTP and gRPC services out of the box.
We also have a Elixir Guild to implement positive changes to our Elixir teams and services, connecting tissue between the squads and giving engineer the ability to collaborate and communicate, evangelise, discuss and learn specific tech topic and to share knowledge and best practices. The guild has also created Churrex, a service project and utils generator, inspired by phx_new.
Frontend: our face on the web
As usual we embrace change. We use React to make frontend web applications. We have a tool to bootstrap React projects, a repository that holds commons components, utilities and workflows shared between the different js apps in Cabify.
Again we have a guild, the Frontend Guild. The main purpose is to share knowledge across frontend teams at the same time it ensures our quality standards are met across shared development efforts. We share a set of good practices and development workflows which are reflected in the frontend guidelines, that aim to illustrate the basic concepts and workflows we follow to make frontend web applications at Cabify.
The Javascript code itself is written using ES6 or Typescript and we use a unified design system thanks to the regular collaboration with the Design FireTeam.
Mobile apps: our face in the cities
We have one mobile app for Riders in Android and iOS and one for Drivers in Android. All apps are mostly native, it allows us to build the best-performing experience for our users. Today, more users use Cabify from their mobile phones than from their browsers, so a first-class mobile experience is a must.
The iOS Rider app is written in Swift. It use XcodeGen to generate the xcodeproj file, which must be run through Mint. The architecture is based on VIPER, VIPER is an application of Clean Architecture to iOS apps.
All Android apps are written in Kotlin. We implement a multi-module architecture and depending on the screen complexity we use different approaches, mostly MVP but we also have parts in MVI an MVVM architectures. We use RxJava for asynchronous programming but Kotlin Coroutines are popping up bit by bit.
Finally we use Firebase Cloud Messaging for messaging and notifications and Firebase Crashlytics as crash reporter.
Data engineering: easing complex data
We continue our journey talking about data engineering weapons. They provide all the reachable data to Product teams. They enhance the awareness of information and thus raise the decision quality of Cabify.
Data Engineering team provide three services: the Data Lake, the Data Warehouse and Lykeion.
All the production MessageBus messages and the CouchDB changes feeds, as well as data obtained from external sources, are published to the analytics PubSub topic. With this information we build our Data lake and Data Warehouse.
The Data Lake is where all the raw information lives, resting on Google Cloud Storage and is built using an Apache Beam job written in Scala.
The Data Warehouse is built on Big Query. Again we have Apache Beam jobs, one written in Python that is in charge of building the schema based on the Data Lake documents, and another in Scala that is in charge of inserting documents from PubSub to BigQuery
To finish, Lykeion is the Cabify’s machine learning platform, a combination of APIs and tools that help the Data Scientist to develop, train, evaluate, compare and deploy machine learning models. Lykeion is written in Python and Scala, it uses Airflow dags to transforming a ML Project into a deployed model. All workflows run in Kubernetes
Test Engineering: simulating cities
We are running test and CI in GitLab, we have unit tests, integration tests, end-to-end tests… With that we were able to obtain information about the quality of our software but the problem has only just begun.
We need to be able to test our platform as it would be in the real world, taking into account the behaviour of the Riders, Drivers and cities and their interactions as if it were a living organism. The task is not easy and requires a new approach: simulating cities.
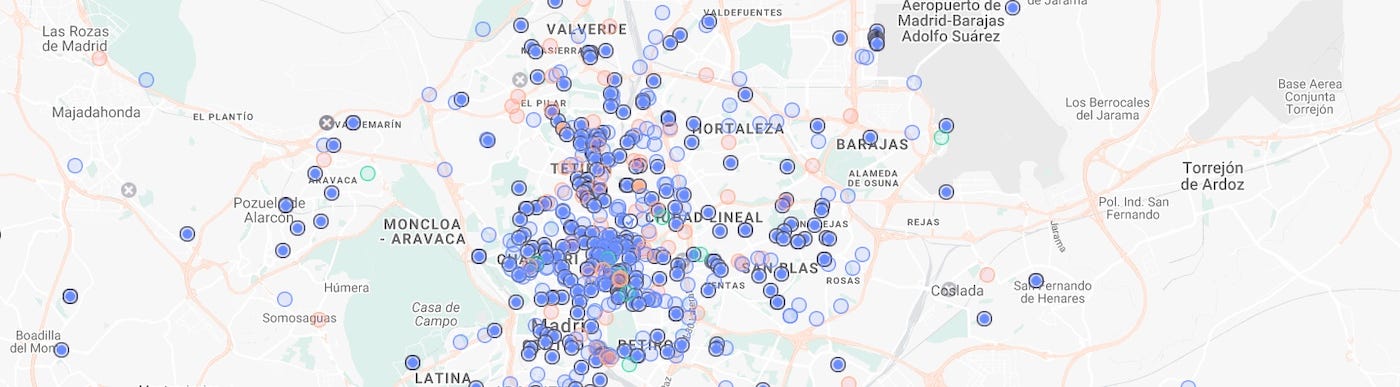
The QA Team automate tasks and processes to be able to test more efficiently. Test Engineering provides “SinCity”, a simulator where to test our stuff under an environment that simulates the real one. They also support all the infrastructure that facilitates simulating and testing.
The QA Team use Elixir and Ruby under the hoods and a bunch of scripts for automated tasks and batch generation of test data.
The journey through the Cabify technology stack ends here. It’s just a high-level picture but if you want to know the details and you want to be part of this, you’re in luck. Check out opportunities and join the Cabify team.
Thanks to our outstanding Design team for the cool header illustration :)

We are hiring!
Join our team and help us transform our cities with sustainable mobility.
Check out the open positions we have in .